
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

 Hello from .conf2017!
Hello from .conf2017!
Splunk User Behavior Analytics (UBA) is a machine learning-powered solution that delivers the answers you need to find unknown threats and anomalous behavior across users, endpoint devices and applications. It not only focuses on external attacks but also the insider threat. Its machine learning algorithms produce actionable results with risk ratings and supporting evidence that augment security operation center (SOC) analysts’ existing techniques for faster action. Additionally, it provides visual pivot points for security analysts and threat hunters to proactively investigate anomalous behavior.
At an uber high level, Splunk UBA addresses the following use cases:
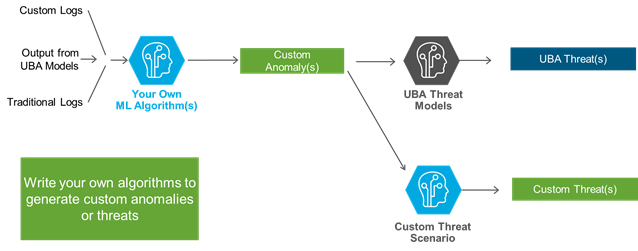
The majority of our customers buy Splunk UBA to address use cases above; there are a handful of customers who have requirements and risks that demand different machine learning models. This may entail edge use cases or extremely verticalized scenarios such as retail fraud or prescription fraud in healthcare organizations. Basically, the ability to ingest custom data and create custom ML models for these use cases is an important use case by itself. And this is one of the most important features of Splunk UBA 4.0 – Machine Learning Software Development Kit (ML-SDK).
With Splunk UBA 4.0, data scientists—regardless of whether they are part of security operations team or not—can write their own machine learning models using Scala or Java programming languages. These custom written ML models have an option to output anomalies into new anomaly categories (data scientists can name these categories to anything they want) or these models can output anomalies into existing forty plus existing anomaly categories, which come out-of-the-box.
But things don’t stop here. Unlike other vendors, Splunk UBA uses a two pass Machine Learning architecture (i.e. all anomalies are fed back to Splunk UBA Threat Detection framework, which runs numerous machine learning models) for it to stitch hundreds of anomalies into actionable threats. This means hundreds of anomalies may get stitched into a single-actionable threat and that too without using any rules.
Interestingly, SOC analysts can also write custom threat scenarios leveraging custom anomaly categories just by themselves, which are powered by their data science team or by stitching custom and out-of-the-box anomaly categories together.
The last and the most important aspect of this feature is - what do these data scientists’ machine learning models ingest? These custom ML models can not only ingest traditional logs or custom logs, but also ingest processed results outputted from other machine learning models—that means you can chain output from one model to another ML, custom or out-of-the-box, to write extremely powerful use cases.
It is important to remember that any UEBA project exists on a continuum, and while Splunk has many advanced customers who have already built out the foundational element (Splunk Enterprise with Splunk Security Essentials app), even before UEBA became a marketing term, not all organizations are required to jump straight into using ML-SDK. We, at Splunk, have found the most repeatable success is when our customers make rapid, but step-by-step, progress to mature their security posture or use cases.
If you are interested in discussing your current use case or desire to elevate your use case with UEBA capabilities and want to leverage ML-SDK then connect with us at sales@splunk.com or talk with any of our security experts. We will help you complete a highly successful UEBA program at no cost and if required, will introduce your data science team with ours to craft some amazing use cases.
Follow all the conversations coming out of #splunkconf17!

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
