
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
Splunk is a powerful tool that can analyze and visualize raw data, in all its forms. Splunk can also combine multiple events to visualize transactions, business processes and sessions. This concept is extremely useful if you want to link multiple events across data sources, that all relate to the same real world event. Let’s explore what this could look like:
In Store Purchase
Imagine a customer tapping their bank card on a payment terminal to purchase something in a shop. This real world event triggers a flurry of events in a large number of systems with the card provider, the bank, and the retailer before the transaction is fully settled. If something goes wrong in any of these systems, the payment might not go through. In this complex transaction, it can be tricky to quickly find the source of the problem. However, Splunk can help join these dots to quickly perform a root cause analysis, and report metrics and KPIs on the service or process being monitored.
Common Splunk search commands for combining events are transaction or stats. An example query could be something like this:
sourcetype=x OR sourcetype=y | transaction sessionID
OR
sourcetype=x OR sourcetype=y | stats range(_time) as duration, count by sessionID
Online Browsing
Another example where this is useful would be for website web server logs. Each page viewed by a visitor would generate an entry in the web server log file. Measuring these alone can be beneficial when ranking page popularity or problematic pages. However, it is of limited value when it comes to measuring things from the user’s perspective. If a user goes to a website and views 100 pages, this should be monitored as one session, as this is one interaction between the user and your company. All KPI’s and metrics should be counted per session, not per page view. The problem is that web server logs do not always contain session information. Calculating and generating session data (sessionization), and maintaining multiple KPIs against these sessions requires a lot of compute. However, it can be done with Splunk by using a combination of queries, lookups and possibly data models.
Firstly, create a query that accurately represents a session based on the information available. For website sessions, the industry standard is to link all visits from a user with a maximum break between interactions of 30 minutes, and a maximum session length of 4 hours. If any of these rules are reached, this will be counted as a new session. Now, what if you don’t have the user information in the data either? The example below generates an artificial user based on the user agent string and the ip address. This is a simple example of device fingerprinting:
index=mywebserverlogs sourcetype=access_combined _index_earliest=-241m@m _index_latest=-1m@m NOT file=* status=200
| eval time=_time
| eval referer = _time."_".referer
| eval request=uri
| fields _time time referer clientip useragent request
| transaction clientip useragent maxpause=30m maxspan=4h keepevicted=f
| eval user=md5(clientip."_".useragent)
| eval http_session=md5(clientip."_".useragent."_"._time)
| stats first(user) as user,
first(time) AS http_session_start,
last(time) AS http_session_end,
count(request) AS http_session_pageviews,
first(duration) as http_session_duration,
first(referer) as http_session_referer,
list(request) AS requests,
list(time) AS times
by _time,http_session
| eval http_session_referer=replace(http_session_referer,"^[0-9]*_","")
| dedup http_session
| table _time,user,http_session,http_session_start,http_session_end,http_session_pageviews,http_session_duration,http_session_referer,requests, times
The above search generates a synthetic user key based on the user agent and client ip for the web request to identify each user. The session key is generated from the user key, with the addition of the _time field.
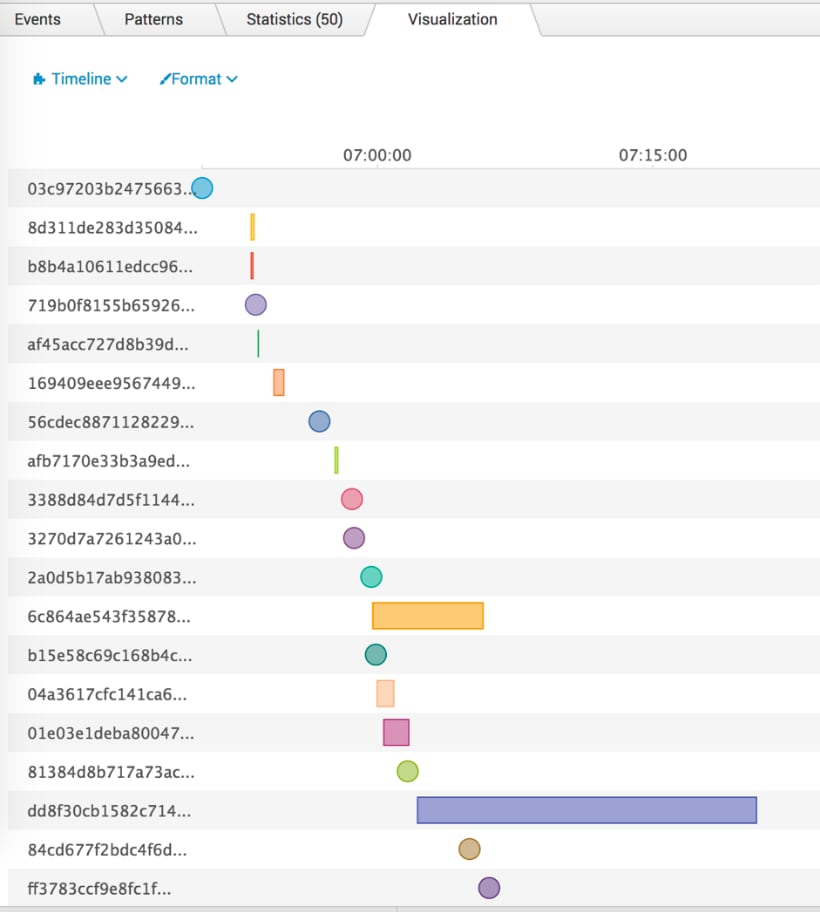
This system can be productionized by appending the output of the above, to a lookup in a scheduled search that runs every 10 minutes. This can be used as a base for searches and make them run much faster:
index=mywebserverlogs sourcetype=access_combined _index_earliest=-11m@m _index_latest=-1m@m NOT file=* status=200
| the sessionization search…
| outputlookup append=t createinapp=t sessions.csv
For each entry in the lookup we calculate some key metrics such as the number of pageviews, duration or referring URL. We can also calculate other useful metrics based on this session data:
Which sessions included the “Add to cart page”? – Good KPI to measure: |inputlookup sessions.csv | stats count(eval(like(requests,"%addtocart%"))) AS AddToCart
Which sessions included the “Checkout success page”? – Conversion rate: |inputlookup sessions.csv | stats count(eval(like(requests,"%checkout/success%"))) AS Checkout
Which sessions included the “Add to cart page” and not the Checkout success page? E.g. Lost revenue or abandoned basket: |inputlookup sessions.csv | stats count(eval(like(requests,"% addtocart %") AND NOT like(requests,"% checkout/success %"))) AS AbandonedBasket
Or combine all three into one search: |inputlookup sessions.csv | timechart span=1h count(eval(like(requests,"%quick-enquiry%"))) AS AddToCart,count(eval(like(requests,"%enquiry-thanks%"))) AS Checkout,count(eval(like(requests,"%quick-enquiry%") AND NOT like(requests,"%enquiry-thanks%"))) AS AbandonedBasket
By doing this we can create a dashboard that contains some of these metrics and present them over time.
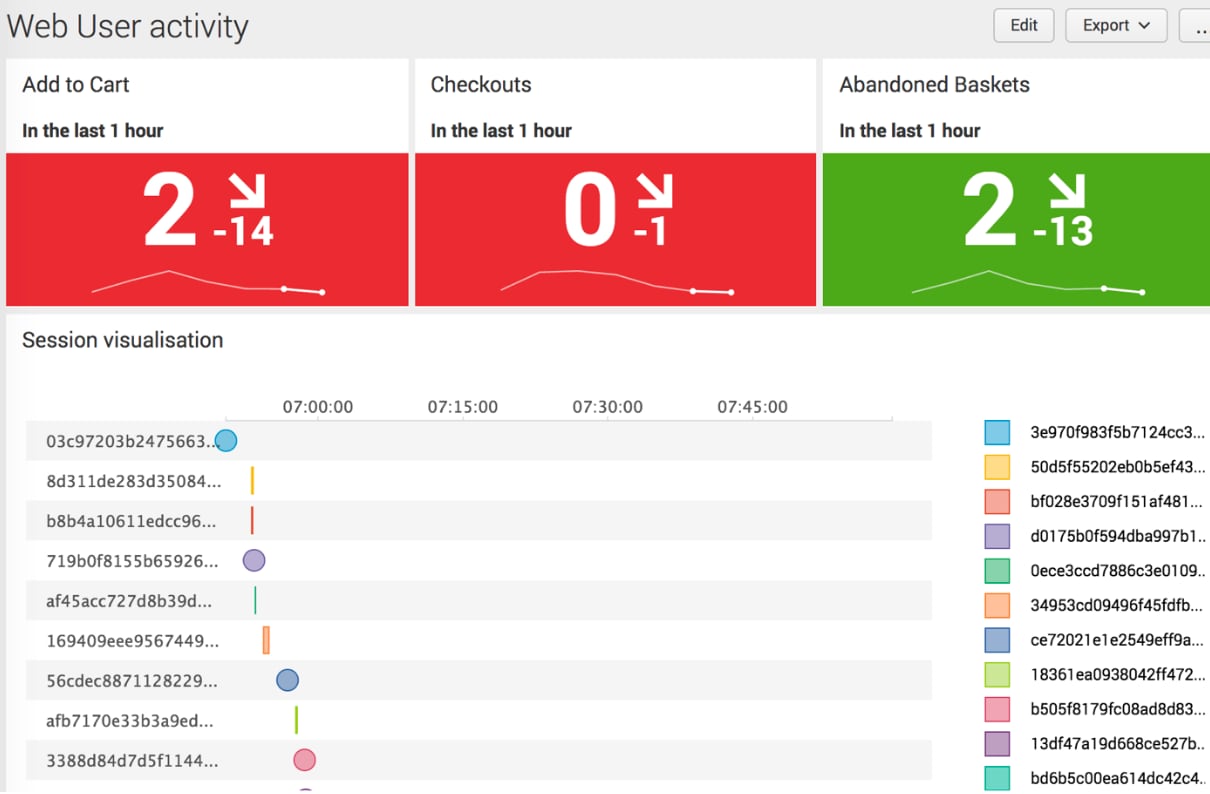
The concept demonstrated above is used heavily in the Splunk App for Web Analytics where web sessions are being generated and stored in a data model. The above timeline vizualisation above can be downloaded from Splunkbase here.
The same concept can be used for order processing, financial transactions, business processes etc. As with everything in Splunk, depending on what data you put in and which questions you ask, you can provide value in all kinds of areas.

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
