
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
The Social Security Administration’s baby names database got some notice recently as the source of this visualisation by Reuben Fischer-Baum
There are a number of different visualisations of this dataset but they all deal with the most popular names.
What if you wanted to dig into the torrid minutiae of the least popular names in America? And what if you wanted to do it with Splunk?
Well, it would be mildly annoying because Splunk has some limitations that make it difficult to work with large historical datasets, but it’s not too hard to make it work:
For Splunk time begins at the Unix epoch – January 1, 1970. Since our dataset starts in 1880, _time has no meaning here and we’ll have to use another field to hold the dates for our events.
Since we can’t set _time how we’d like to, Splunk defaults _time to the mod time of each file. You’ve just downloaded and unzipped the files from the SSA, so they all have the same mod time. Splunk will attempt to set the same timestamp on every event. Unfortunately, Splunk has trouble when there are too many events with the same timestamp. YMMV – when I first built the babbynames app with version 4.3, the error I received was “The search failed. More than 3125000 events found at time 1284355500”. As of 2012, the dataset has > 7 million events.
One way to get Splunk to consume this dataset in a useable form is to set the mod time of each file to something different, so that there aren’t too many events with the same timestamp.
Now we can glean some truly astonishing insights from this dataset:
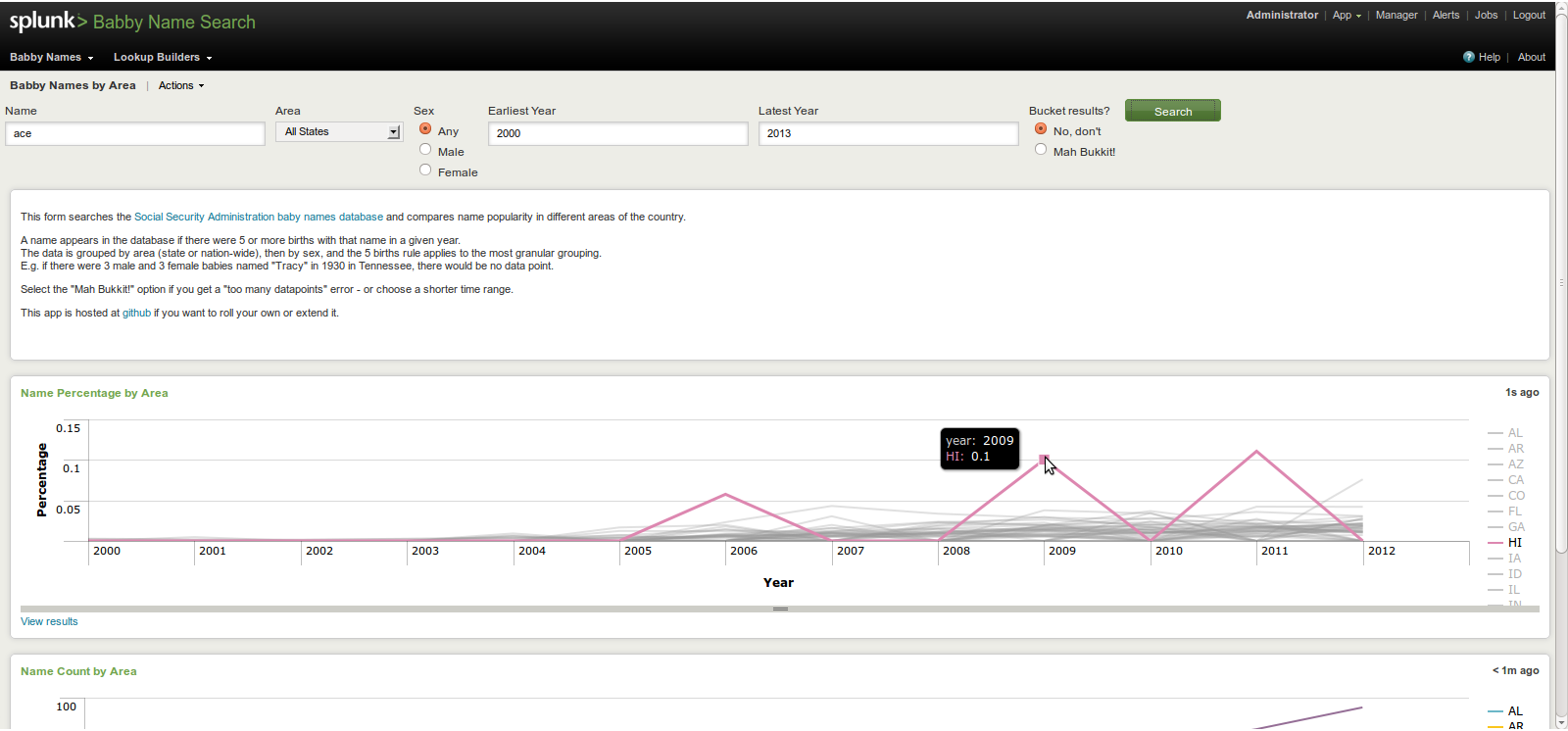
Ace is pretty big in Hawaii:
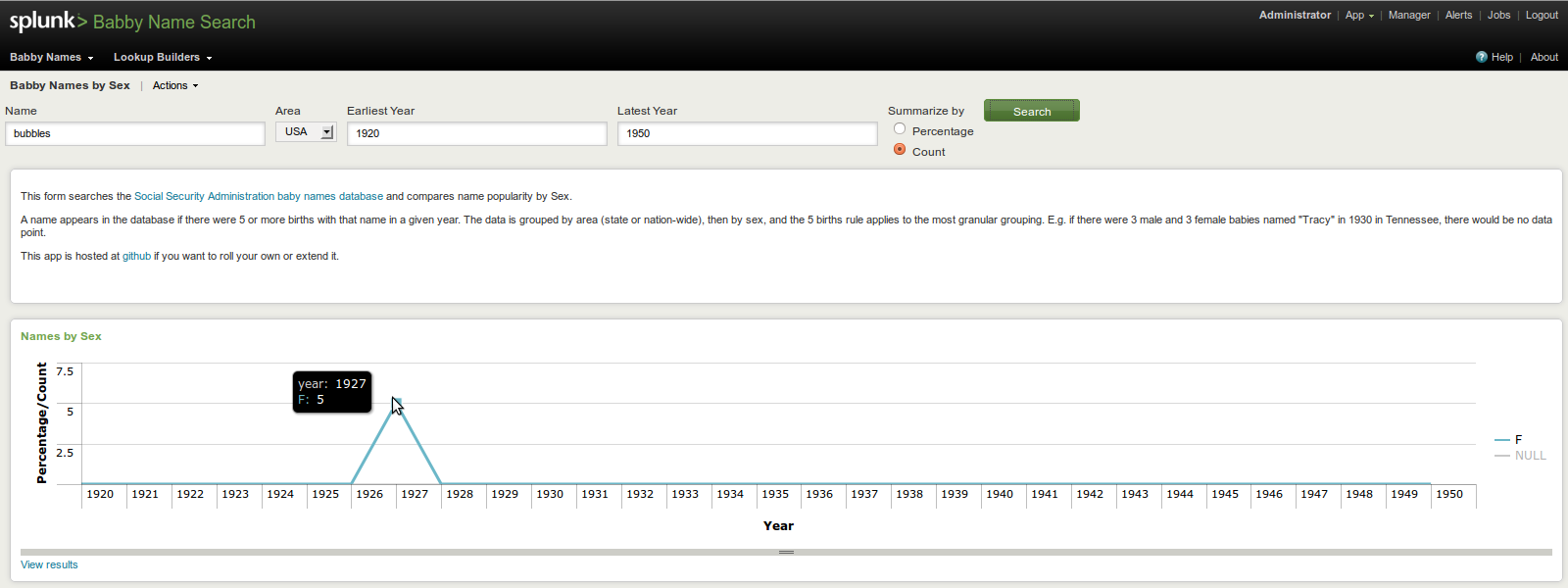
5 parents in 1927 named their daughters Bubbles:
A sample app is available at https://github.com/firebus/splunk-babbynames.
If you don’t want to go through the hassle of indexing the data, drop me a line and I’ll give you mine.
----------------------------------------------------
Thanks!
Russell Uman

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
